Yes! Agile teams plan
Agile teams plan, and they plan often. Every Scrum team plans at the start of each sprint during sprint planning. Sprint plans live in a sprint backlog. Teams then plan each day during the daily scrum, basing what they will do next on what they accomplished the day before and adjusting their work to deal with dependencies or obstacles.
Many agile teams also plan further ahead, whether they call it release planning, quarterly planning, PI planning, mid-range planning, or milestone planning. Milestone plans are often expressed as a range of product backlog items that can be delivered by a future date.
Teams have longer range product plans as well. Product plans are represented by the entire product backlog.
Milestone and product plans are revised at the end of each sprint. The revised plans reflect the team’s velocity and any new or emerging work uncovered during the sprint and sprint review. Beyond that teams may participate in portfolio and strategic planning.
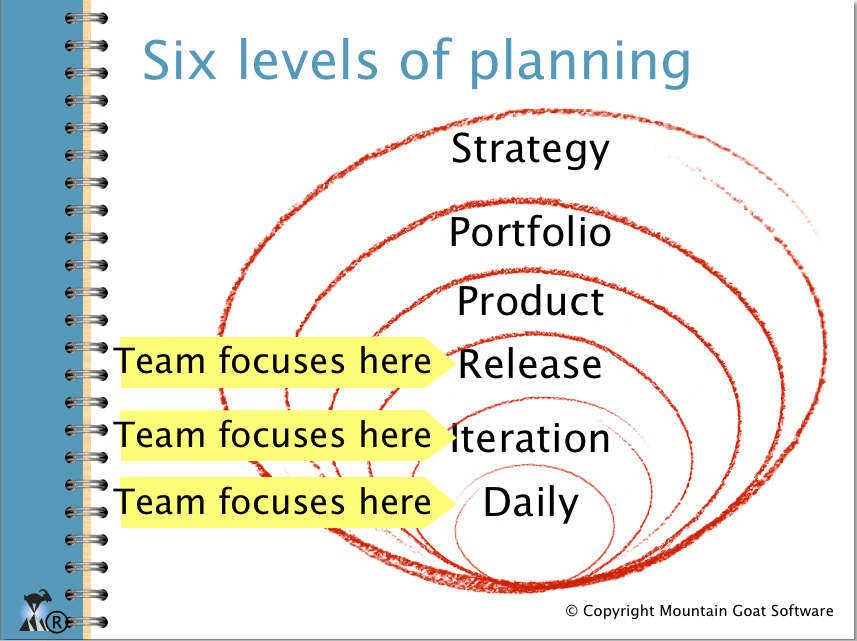
You can think of these many interrelated layers as a planning onion.
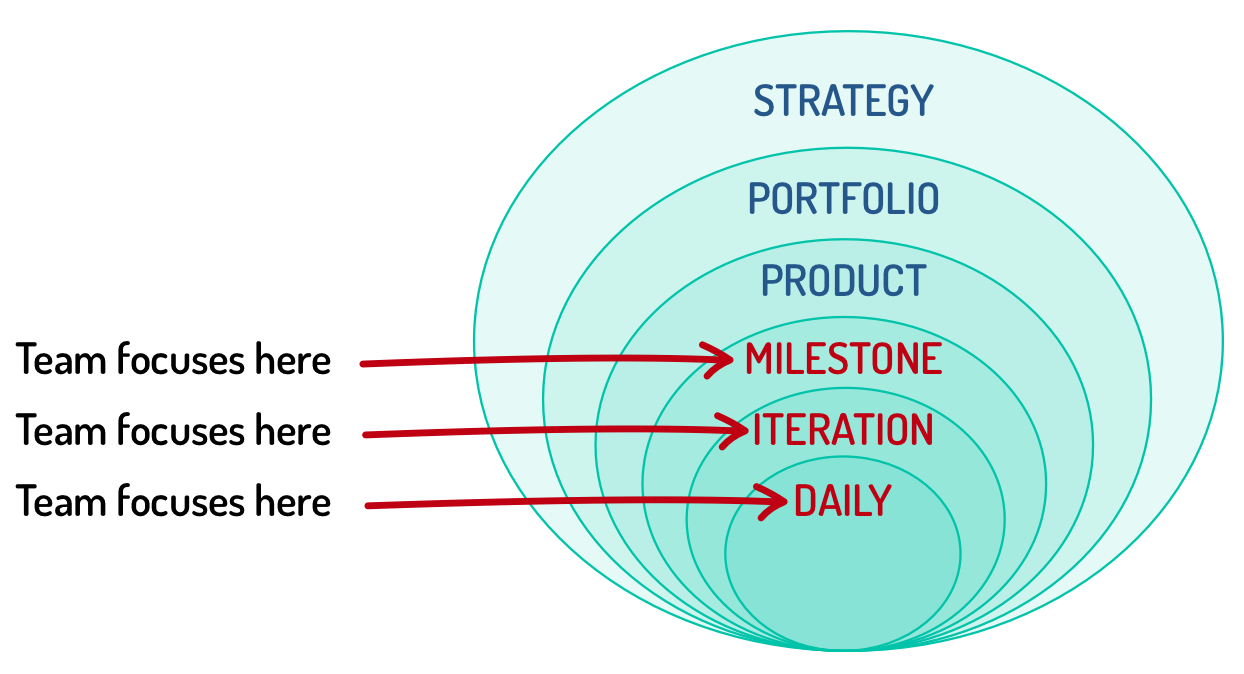
When most teams refer to agile planning, they are talking about sprint (iteration) planning and milestone planning.
Ask GoatBot your agile planning questions
Overview of sprint and milestone planning
Sprint planning is also known as iteration planning. This planning level is concerned with how to deliver an increment of value (sprint goal)that contributes to the overall product goal, during a short time period (weeks).
Sprint planning happens at the beginning of each sprint and involves the full Scrum team. Sprint plans are expressed as the sprint backlog. To understand how much work they can accomplish in a given sprint, teams consider team capacity, their approach to the work, who is available to work on it, and the amount of time it will take to finish the work. This is known as capacity-driven sprint planning.
Milestone planning, historically called release planning, usually spans several months. Milestone plans encompass multiple sprints (or iterations) that together achieve some bigger goal or cohesive set of functionality for the end user.
Milestone plans typically take the form of a visual demarcation in the product backlog. They can also be visualized on a story map or a roadmap.
Milestone vs release planning
The term release plan made a lot more sense when Scrum first began. At that time, most teams would run one or (usually) more sprints and then release a product.
Today, most teams release more often than every few sprints. Some release every sprint and others release multiple times per sprint or even many times per day.
Release plan might be an outdated term, but being able to predict what will be delivered three, six, or perhaps more months into the future is still essential for some teams. The agile world has yet to come to a consensus on what to call those longer term predictions.
SAFe has separated the idea of planning vs releasing with the idea of a PI (Planning Interval). A PI contains a set of work that will be delivered over several iterations. During a PI some businesses release frequently; others might only release once or twice. It depends on their context.
I prefer to avoid complicated scaling and agile release train (ART) terminology. I use the terms milestone planning or quarterly planning to refer to looking ahead several sprints and making a prediction of what will be delivered by then.
Why create milestone plans?
To understand why teams create milestone plans, even though the plans will likely change, it might help to consider why people plan hiking excursions.
Colorado boasts North America’s greatest concentration of mountain peaks over 14,000 feet (nearly 4,300 meters) or “fourteeners.” Most of Colorado’s fourteeners are non-technical routes: no special equipment is needed and anyone in good shape can make it to the summit. This means there are a couple of different ways to climb a fourteener.
One approach is to drive to the base of the mountain and start walking toward the highest thing you see. This will almost certainly be a false peak—once you’ve reached it, you’ll see a higher point that had been obscured by the false peak.
So you walk again toward the highest point you see. It, too, will probably be a false peak. It’s an inefficient way to hike. Every time you reach a false peak, you have to descend and then ascend again. Keep this up long enough, though, and you’ll eventually find the true summit.
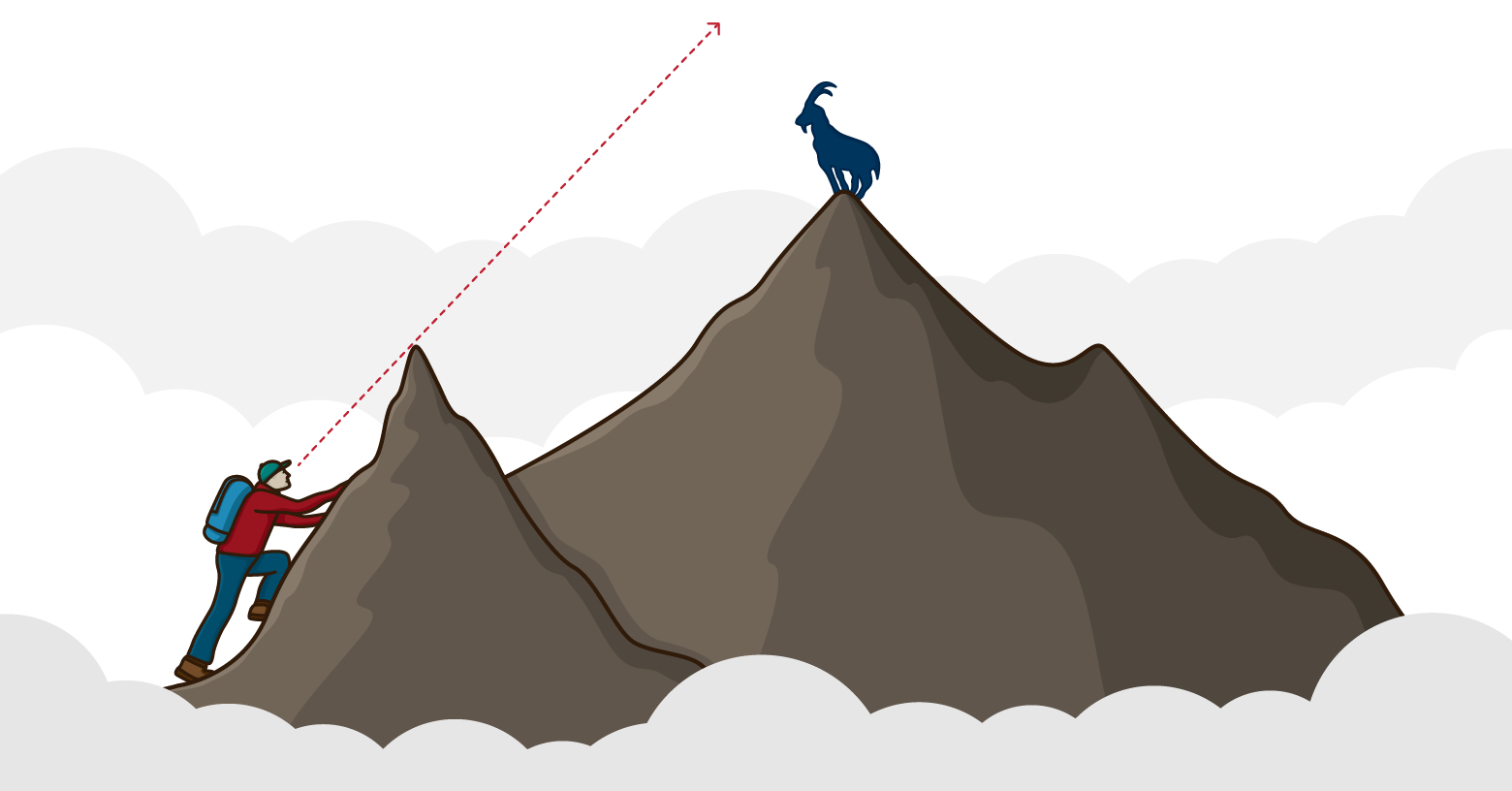
A second way to climb a fourteener is to purchase a topographic map, identify a route up the mountain, and then proceed that way. Looking at a topographic map allows you to plot a course to the summit that avoids much of the inefficiency of the first approach.
Of course, you must be careful not to value that route plan too highly—a stream you plan to cross may be too deep when you arrive. A rock slide may have made a trail impassable. You will likely need to alter the original route when you encounter problems.
In the same way, quarterly and mid-range plans help teams be more efficient in their work and help others outside the team get a sense of what they can expect. They also help teams avoid finishing a series of sprints and feeling that, while they always worked on the highest priority items, the collection of work completed does not add up to a satisfying whole.
One way to communicate milestone plans
People inside and outside of an organization need to know approximately how much functionality they can expect by a certain date. A simple way to calculate and communicate that information is by using a team’s velocity and the product backlog.
Scrum teams who are estimating with story points can track their velocities (number of story points delivered per sprint) and base their predictions on that. A common approach is to use a team’s average velocity—but far better is to use a velocity range.
You can eyeball a velocity chart like the one shown below. Alternatively, you can use the velocity range calculator on our website.
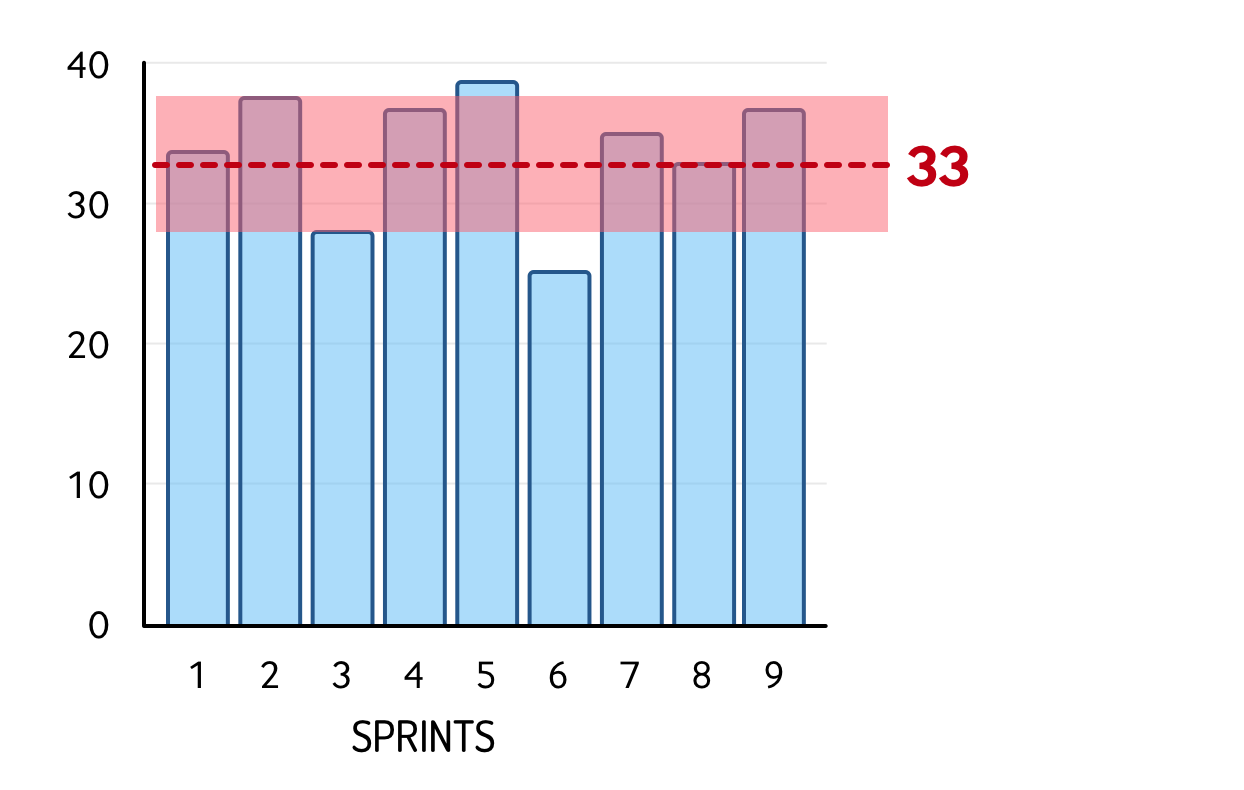
This graph shows a team with an average velocity of 33 during the nine sprints they’ve worked together. More importantly, a mean velocity range has been identified: from 27 to 36, as indicated by the shaded area.
The low and high values of the range can be used to communicate how much can be delivered by a desired date. Suppose someone has asked this team to say how much can be delivered in five sprints. They would answer that by drawing two arrows pointing to different depths of their prioritized product backlog as shown in the following illustration.
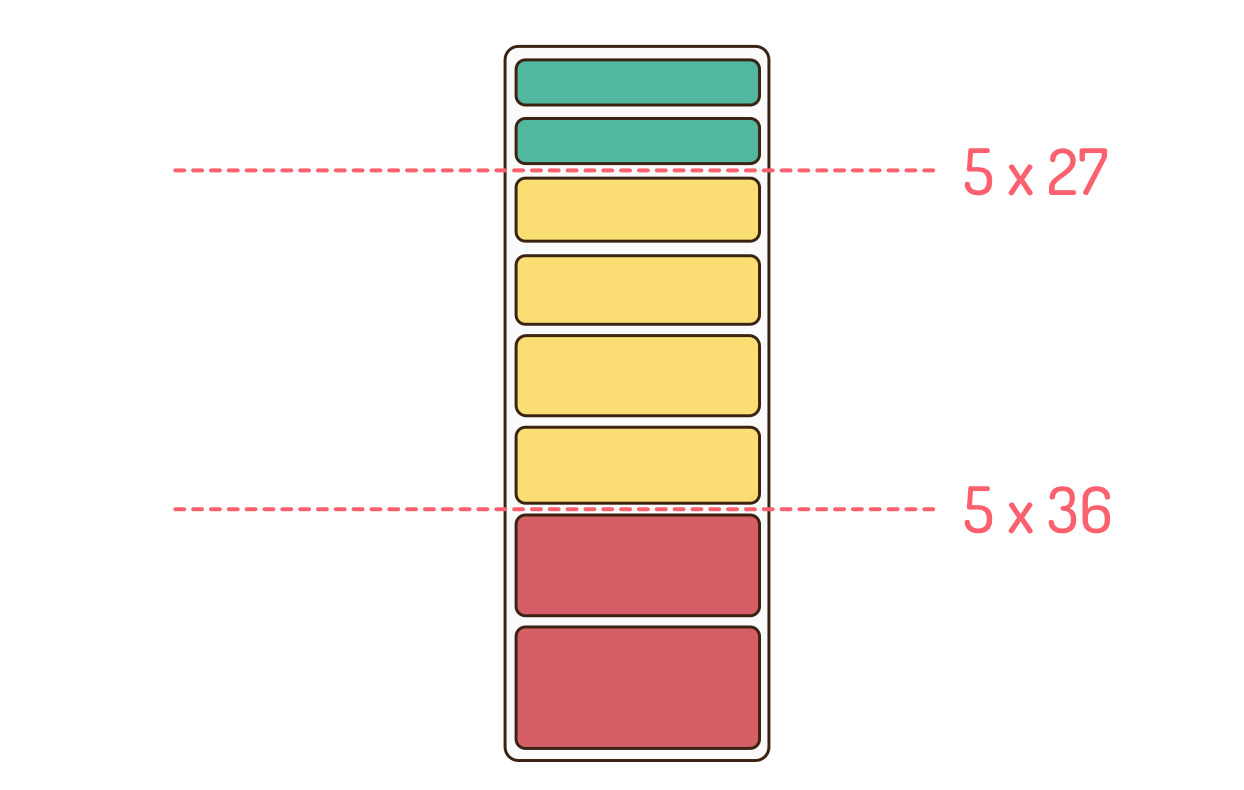
In this figure, the product backlog is shown as a stack of boxes. The top arrow is drawn after counting down a number of story points equal to the number of sprints (five, in this case) multiplied by the low velocity (27). The bottom arrow is set equal to that same number of sprints multiplied by the high estimate of velocity (36).
Ideally you would communicate to stakeholders that 135 to 180 points will be delivered in the coming five sprints. You’re much more likely to keep your promises when you promise a range. If stakeholders can’t handle a range, you will probably want to convey a single value somewhere between the low and high totals, perhaps 160 in this case.
Agile planning is built into Scrum
Agile plans are an essential part of all agile frameworks. In Scrum, every sprint begins with sprint planning, in which teams decide what work they can commit to completing during the timebox. Then they express that work as the sprint backlog.
The daily scrum is an opportunity for the team to inspect their progress toward the sprint goal and adapt the plan accordingly.
The sprint review gives agile teams, stakeholders, and product owners a chance to inspect the functionality the team has delivered so far and adjust their milestone plans and product plans accordingly. That information might also filter up to portfolio and strategic plans.
When you are ready, Mountain Goat Software offers training in agile planning and agile estimation to help teams create the accurate plans your business requires.
Last update: September 4th, 2025
Recommended Resources