
Bugs can creep in through the smallest crack. And the hole between our development database and the production database was letting in far too many of them. During development, we would test and test and test. With extreme confidence and satisfaction, we’d release to production. But without fail, only a few hours after we released the new version of our call center software, we’d get our first bug report. Was our testing at fault? Nope. Our change management system was. And it was causing some big (and embarrassing) problems.
In one particular case, we added a column to a table in the development database—but we forgot to move that change to the production database. As a result, database searches retrieved results in the wrong order: the address was in a field for the state, the state was in a field for ZIP code, etc. In another case, we added an index to the development database to improve performance. We talked it up to the users, telling them about the amazing performance gains they’d see. But, oops! We forgot to add the index to the production database.
These weren’t bugs that we were missing in testing. These were bugs that showed up when changes made in our development and test databases never made it onto the production databases. We had to fix this. Fast.
We couldn’t just admonish everyone to be careful with database changes. We needed a fail-safe way to ensure that the production database was identical to our development databases. With a small database, it’s easy to simply export the data, delete the database, create the new version of the database, and import the data back into it. But, because we were a 24 × 7 operation with a terabyte of data located in four U.S. call centers, that option wasn’t available to us. We eventually settled on two combined techniques that eliminated this entire class of bug for us: database versioning and database differencing.
Database Versioning
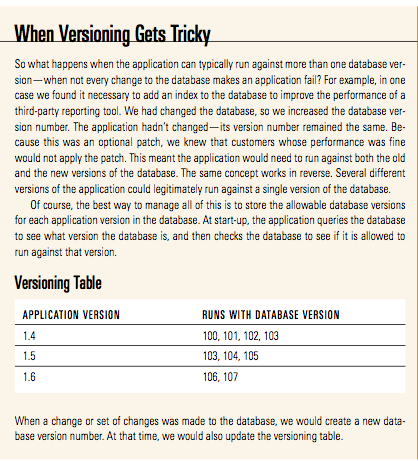
The first thing we did was to apply a version number to the database—a separate number from the one we gave the application. In exactly the same way that we increased the application version number whenever the application changed, we also changed the database version number anytime the structure of the database changed. In other words, whenever we’d add such things as a new column, table, index, or stored procedure, or a set of these changes together, we would change the database version number.
We then constrained the application so that it would start only when connected to a database with a proper version number. The beauty of this was that if the application started and passed this check, we knew it was running against an appropriate version of the database. This method worked well as a smoke test for newly deployed applications. It also worked well if anyone accidentally tried to run an old version of the application.
Database Differencing
Using database versioning was a huge step forward, but it had not solved the problem. What if we forgot to increase the database version number after making a small change to the database? How could we tell a database had changed, if the version number had not?
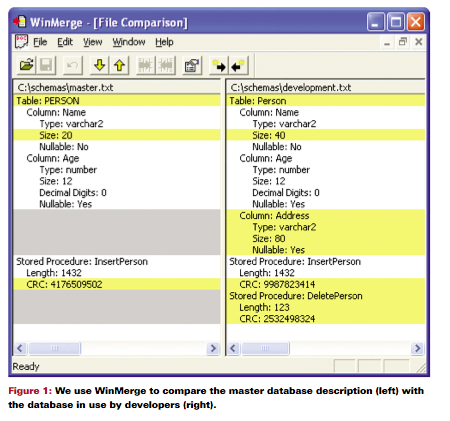
We needed a way to compare any development database against the master database. To automate the comparison, we wrote a program that creates a text file description of a database. This text file lists everything relevant to the correct performance of our applications—table names, column names and sizes, stored procedures, etc. Equipped with a file describing one database, you can easily compare it against any other database by generating a text description of the second database. There are many utilities available for comparing two text files and identifying differences. We like WinMerge, shown in Figure 1 (on page 13) comparing two databases.
The left portion of Figure 1 describes the master database. It has one table (called Person) with columns labeled Name and Age. Name is a variable-length array of characters up to a maximum of twenty. The Age column is a number up to twelve digits in length, and it is “nullable,” meaning that the database will allow it to hold empty (or null) values. However, the name column is not nullable.
The database on the left also contains one stored procedure, which is a block of code that resides in the database but may be invoked by external programs. In this database, the stored procedure is called InsertPerson.
It is important to check for more than just the existence of the stored procedure, because the program code of the stored procedure may be different between two databases. That’s why we calculate a cyclic redundancy check (CRC) value for the stored procedure. A CRC value is a number that can be calculated from any character string. If any piece of the string changes, the CRC value will change. This means that if a programmer makes even a one-character edit to the stored procedure, the CRC value will be different.
We then generate a text file for another database, in this case the database under development. The right portion of Figure 1 describes the development database. Yellow lines indicate differences between the two files. It is easy to see that the programmers increased the size of the Name column and added an Address column to the database on the right. They’ve also changed the contents of the InsertPerson stored procedure and added a new stored procedure, DeletePerson.
Armed with this kind of information, you can reconcile the differences between these two databases and make sure that everyone—programmers, testers, and end users—has the same database.
Lessons Learned
Problems caused by slight differences between databases can be very difficult to track down. Differences are often subtle and aren’t usually the first thing you think of when a new bug is found. The two techniques we’ve described will give you confidence that the combination of application and database on a production machine is at least the one you’ve tested.
Killing Two Bugs with One Program
Comparing databases also helped us identify problems at remote customer sites. Frequently, customers will buy our product, install it, and then customize it in unsupported ways. Whenever these customers report problems that could be related to the database, we have them run this program and send us the resulting text description of their database. It is not uncommon to find that they have added or deleted indexes, added columns, or changed stored procedures. Because our program generates text files and does not require simultaneous connections to both databases, we are able to find problems such as these, even with remote databases.
Kristy Hill is an Oracle Database Administrator with eight years of experience in her field. She has co-authored a book with Mike Cohn. Kristy is currently working for Visualize, Inc., and is engrossed in the challenges that genetics research places on databases
Last update: January 7th, 2022





